参考LoRA(Low-Rank Adaptation)详解 – 知乎
这个算法属于PEFT(Parameter Efficient Fine-tuning),在此之前还有提示学习(Prompt Learning)和适配器学习(Adapter Learning)(也许以后填坑吧)
这俩的缺点大概就是prompt的依赖性和adapter引入的额外推理时间
LoRA(Low Rank Adaptation)的核心思想是基于低秩的适配器进行优化
秩的背景知识
矩阵的秩可以通过行秩或列秩计算(这俩数值相等),行秩即矩阵中线性无关的行的个数
这里存在一个定义叫做过参数化,即深度网络中的矩阵(比如用一个矩阵表示全连接层)的维度是超出了实际的特征维度的,即可以用更小的维度去表示有效信息(内在维度)。可以理解成我们希望找到这个过参数化的矩阵的内在维度,找到一个满秩的子矩阵。
总结而言秩和过参数化的现象有两点:
- 一旦我们找到了足够解决问题的参数空间,再增加这个参数空间的大小并不会显著提升模型的性能
- 一个过参数的模型的参数空间是有压缩的空间的,这也就是LoRA的提出动机
LoRA的细节
计算原理
假设我们要fine-tune原模型的某一层,即一个矩阵$W$ ,此时我们在$W$旁边插入一个并行的权值矩阵$\Delta W \in R^{d\times k}$ ,并对这个$\Delta W$ 做低秩分解,得到$B \in R^{d\times r}$和$A \in R^{r\times k}$,其中$r \ll min(d,k)$构成新的前向公式如下:
$$
h=Wx+\Delta Wx=(W + \Delta W)x=Wx + BAx
$$
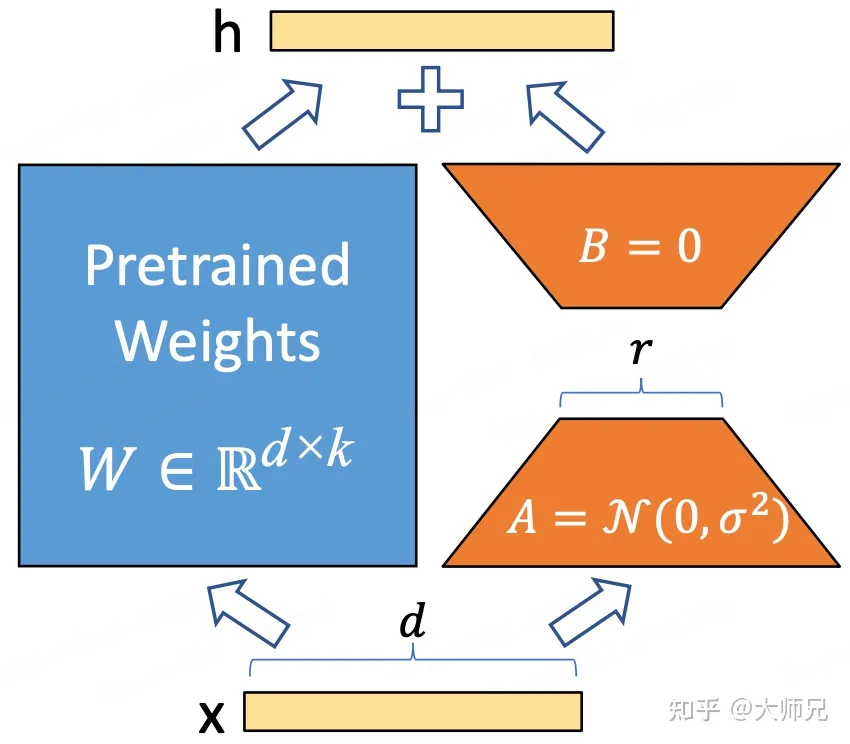
训练细节
在初始化时,A使用高斯初始化,B使用零矩阵进行初始化,r通常采用一个非常小的值(1、2、4、8这种就可以)
零矩阵初始化的问题:目的是数据第一次通过网络时,输出与预训练模型的输出一致
根据苏剑林梯度视角下的LoRA:简介、分析、猜测及推广 – 科学空间|Scientific Spaces的说法,这样一个非0一个全0会带来初始化不对称
一种都用非0矩阵初始化的方法是事先将预训练权重减去初始化的值$$
W=W_0-B_0A_0 +BA
$$
这里放一个LoRA的代码样例:
input_dim = 768 # 例如,预训练模型的隐藏大小
output_dim = 768 # 例如,层的输出大小
rank = 8 # 低秩适应的等级'r'
W = ... # 来自预训练网络的权重,形状为 input_dim x output_dim
W_A = nn.Parameter(torch.empty(input_dim, rank)) # LoRA权重A
W_B = nn.Parameter(torch.empty(rank, output_dim)) # LoRA权重B
# 初始化LoRA权重
nn.init.kaiming_uniform_(W_A, a=math.sqrt(5))
nn.init.zeros_(W_B)
def regular_forward_matmul(x, W):
h = x @ W
return h
def lora_forward_matmul(x, W, W_A, W_B):
h = x @ W # 常规矩阵乘法
h += x @ (W_A @ W_B) * alpha # 使用缩放的LoRA权重,有助于在变化r时减少重新调整超参数的需求
return h
Transformer中的LoRA
原文中对Transformer中的权值矩阵做了个对比试验
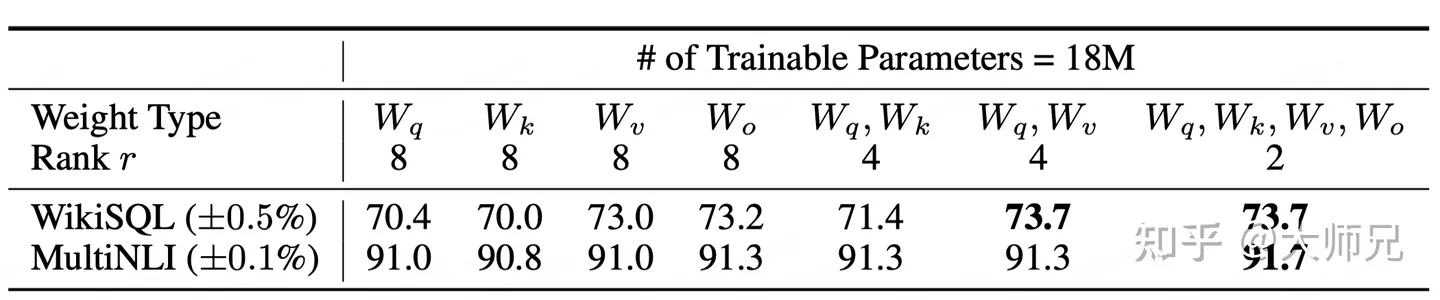 看起来还是全加最好
看起来还是全加最好
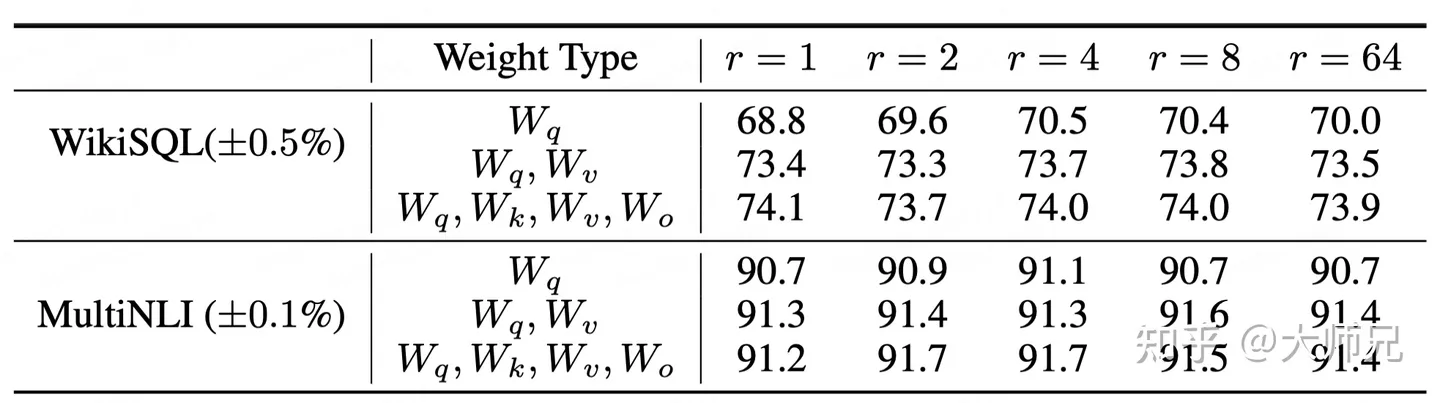
秩的选择
结论:1-8一般就可以达到最优解,再大并没有多少提升
优缺点总结
- 优点:不增加推理时间、不更改原始参数
- 缺点:仅适配当前任务,对于多任务场景需要多次训练